0. まずは導入:LLMに「もう一回言って?」を“プロンプト側”でやる
LLMを使っていて、こんな体験はありませんか?
- 同じ質問を投げたのに、1回目はズレた答え、2回目は急に当たる
- 長い入力(箇条書き、候補、表っぽい羅列など)だと、どこかを読み落とす
この論文は、その「2回目のほうが当たりやすい」現象を1回の問い合わせの中で再現するアイデアを検証しています。
やることは極端にシンプルで、入力をこう変えるだけです。
(通常) <QUERY>
(提案) <QUERY><QUERY> ← 質問文を丸ごと2回つなげる
1. この論文が言っていること(3行まとめ)
- LLMは多くの場合、**左から右へ順番に読む(causal LM)**仕組みで、入力の並び順が性能に影響する
- そこで、質問文を 2回繰り返すと、2回目の読み込みで「1回目の全文」を参照でき、理解が安定する
- 実験では、推論をさせない条件で、複数モデル・複数タスクにおいて統計的に有意な改善が多数確認された
- しかも 出力トークン数(返答の長さ)やレイテンシ(体感速度)がほぼ増えないと報告
2. 背景:なぜ順序が効くのか(専門外向けに最小限)
論文の鍵は「多くのLLMは causal language model として学習されている」という点です。
これは乱暴に言うと、
- 入力を 左→右に処理する
- 早い位置のトークン(単語)は、後ろの情報を“未来”として参照できない
という性質です。
だから、たとえば多肢選択問題で
- question-first:質問 → 選択肢
- options-first:選択肢 → 質問(=選択肢を読む時点で質問が見えていない)
のように順序を変えると、モデルの当たりやすさが変わります。
この論文は、順序問題の“抜け道”として
同じ質問をもう一度読ませる(=2周目)
を提案します。2回目の質問トークンは、1回目の全文を参照できるので、結果として「全体を見渡した状態」で回答しやすくなる、という説明です。
3. 方法:何をどう比べたのか(実験設計を“記事向け”に整理)
3.1 対象モデル(7つ)
論文では、主要プロバイダの 7モデルを対象にしています(2025年2〜3月、公式APIで実行)。
- Gemini 2.0 Flash / Gemini 2.0 Flash Lite
- GPT-4o / GPT-4o-mini
- Claude 3 Haiku / Claude 3.7 Sonnet
- Deepseek V3
3.2 ベンチマーク(7つ + 形式違い)
標準ベンチマーク5つ + 独自2つ(NameIndex / MiddleMatch)。
- ARC (Challenge), OpenBookQA, GSM8K, MMLU-Pro, MATH
- 独自:NameIndex, MiddleMatch(後述)
さらに、ARC / OpenBookQA / MMLU-Pro(多肢選択系)は
- question-first
- options-first
の2形式で実験しています。
ここがポイント:
多肢選択3種が「2形式」なので、ベンチ構成は実質 10パターン(2+2+2+1+1+1+1)になり、
7モデル×10パターン = 70テスト という数え方になります。
3.3 勝ち負けの判定(統計)
「改善したっぽい」ではなく、**McNemar検定(p<0.1)**で有意差を見て「勝ち」を数えています。
4. 結果:図1〜図4の読み方(ここがこの記事のメイン)
以下は、論文の図を「読者が迷わない」ことを最優先に、見どころ→解釈の順で説明します。
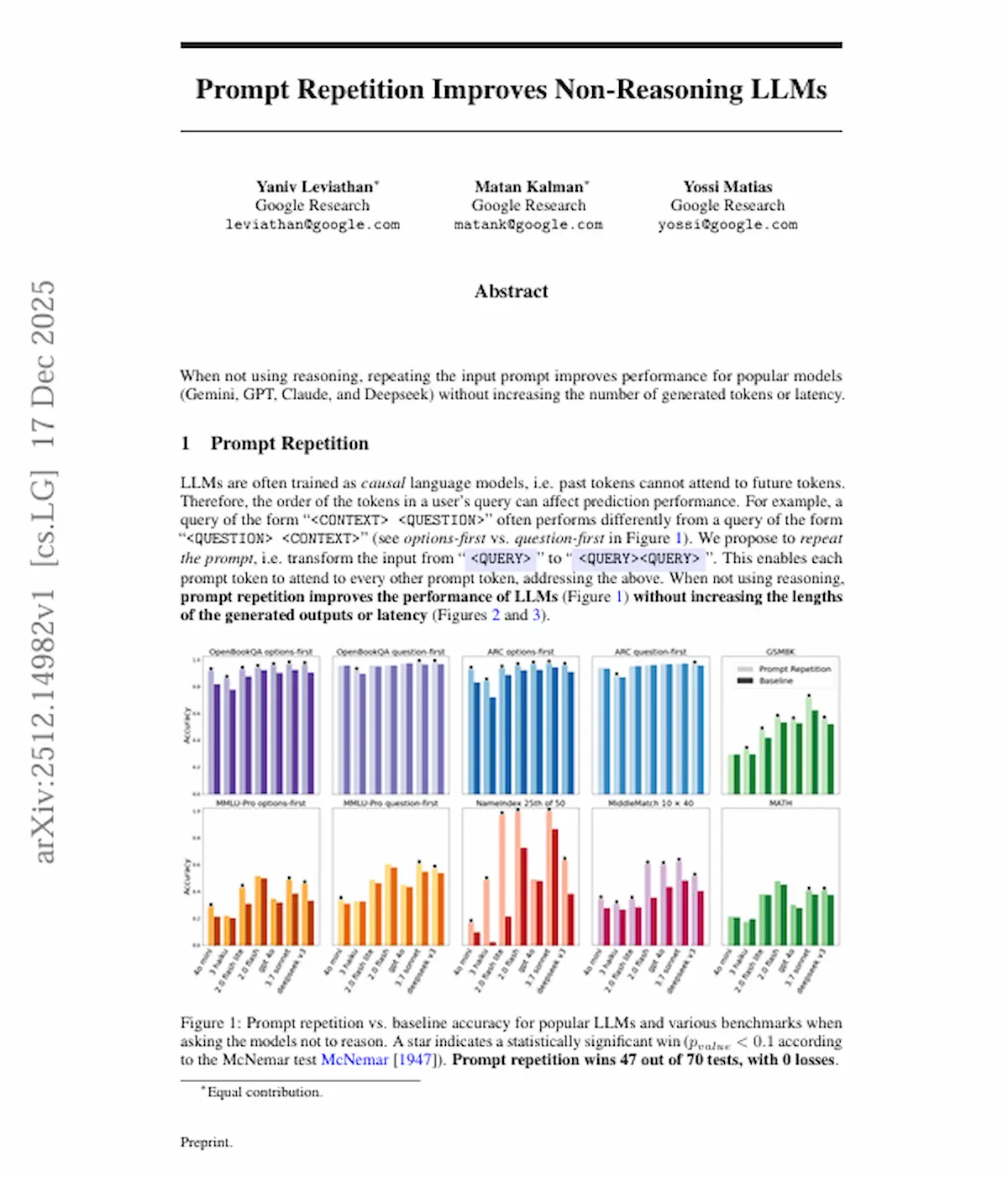
図1の読み方:まずは“効くかどうか”の総まとめ
図1は何を示す?
- 推論させない(= step-by-stepを要求しない)条件で
- Baseline(通常プロンプト) vs Prompt Repetition(2回反復)の正答率を比較
図1の見方
- 棒(または点)の高さ=正答率
- **★(星)**=統計的に有意な改善(McNemar検定 p<0.1)
図1の重要な数字(論文が明示)
- 70テスト中、47が有意に改善(47勝)
- 悪化(敗北)は0
つまり、「効くことが多く、少なくともこの範囲では“外して悪化する”例が見えていない」
というのが図1のメッセージです。
図1の“効きやすい場面”の傾向
論文は、特に
- **options-first(選択肢→質問)**で改善が大きい
- **question-first(質問→選択肢)**では改善が小さめ
と述べています。
直感的には、options-firstは「質問を見ないまま選択肢を処理する」局面があるので、2回目に読む効果が出やすい、という理解です。
図1で目を引く例:NameIndexでの劇的改善
論文中で具体的に挙げられている例として、
- Gemini 2.0 Flash-Lite × NameIndex
- Baseline:21.33%
- Prompt Repetition:97.33%
という大きな改善が報告されています。
図2・図3の読み方:“精度以外”も増えないの?
図2・図3はセットで、扱っている指標が同じです(紙面の都合で分かれているイメージです)。
図2・図3は何を示す?
各ベンチマークごとに、
- Accuracy(正答率)
- Response length(出力の長さ:平均/中央値)
- Latency(レイテンシ:応答時間)
を、複数の手法で比較しています。
比較されている手法(ざっくり)
- Baseline(通常)
- Prompt Repetition(2回)
- Prompt Repetition (Verbose)(「繰り返します」を挟む)
- Prompt Repetition ×3(3回)
- Padding(ドット等で長さだけ水増し)
- そして参考として:Think step by step(推論を促す)
図2・図3の結論(論文の主張をそのまま言うと)
- Prompt Repetition系(2回/Verbose/×3)は、出力の長さを増やさない
→ “回答フォーマットが変わらない”ので、既存システムに入れやすい - レイテンシも基本は増えない(入力処理=prefillが増えるだけで並列化できる、という説明)
- ただし例外として、非常に長い入力(NameIndex / MiddleMatch、または×3)では
Claude系モデルでレイテンシ増加が見られたと記載
「Paddingが効かない」意味
ここは重要で、論文は
伸びたのは“入力が長いから”ではなく、同じ内容をもう一度提示したから
だと示すためにPaddingを入れています。
Padding(無意味な文字で長さだけ揃える)は改善しない、という結果が書かれています。
“Think step by step”との違い(読者が一番知りたいところ)
図2・図3では、推論を促すと
- 出力が長くなる
- レイテンシが大きくなる
(=コストと時間が増える)
一方でPrompt Repetitionは、少なくともこの実験範囲では
- 精度が上がるのに
- 出力の長さもレイテンシもほぼ増えない
という対比が強調されています。
ここが“使いどころ”の分かれ目:
- 推論が必要な難問 → step-by-stepが効くが重い
- 推論させないQ&A/分類/選択 → Prompt Repetitionが軽く効く可能性
図4の読み方:推論(step-by-step)をさせるとどうなる?
図4は何を示す?
- 「Think step by step」と促して推論ありにした条件で
- Baseline vs Prompt Repetition の精度比較
図4の数字(論文が明示)
- 28テスト中、5勝・1敗(残りは有意差なし)
本文では「5 wins, 1 loss, 22 neutral」と表現されています(合計28)。
なぜ効きにくい?
論文は、
推論過程の出力が、そもそも質問文の言い直し(反復)から始まることが多い
だから、入力側で反復しても追加メリットが小さい
という説明をしています。
5. 独自ベンチマーク(NameIndex / MiddleMatch)をやさしく説明
この論文は、反復の効きを“分かりやすく見せる”ための独自タスクも用意しています。
NameIndex(N=50, i=25)
- 50個の名前が並んだリストを与える
- 「25番目の名前は?」と聞く
人間でも数え間違いが起きやすいタイプのタスクで、モデルが読み飛ばすと外しやすい。
反復による改善が強く出た、という位置づけです。
MiddleMatch(N=40, K=10)
- 40個の要素(名前 or 数字)からなる列を与える
- 要素は10種類しかない(K=10)ので、列の中で繰り返しが起きる
- 「AとBの“ちょうど間”にある単一の要素は?」を答える
こちらも、列全体の把握が甘いと間違えやすく、反復で改善が出やすい設計です。
6. 実務での使い方(コピペできる形に)
最小テンプレ(これだけ)
<QUERY>
<QUERY>
多肢選択の例(論文のテンプレ趣旨を短く)
- 返答形式(例:「The answer is A.」のように出力を固定)を変えずに
- 入力側だけを2回繰り返す
システム側で「ユーザが入力した質問を裏で2回にして投げる」ことも可能で、
出力フォーマットを壊さずに“ドロップイン”しやすい、というのが論文の推しポイントです。
7. 注意点(論文の範囲で言えること/言えないこと)
- 論文は「出力トークン数やレイテンシは増えない(例外あり)」と報告していますが、
入力トークン数は増えるので、API課金が入力にも乗る場合はコスト増の可能性があります
(論文は主に“生成側コスト”の観点で議論しています)。 - 長いプロンプトでは、そもそも反復が入力長制限に引っかかって難しい場合があります(論文でも注意書きあり)。
- 推論(step-by-step)を使う場面では効果が弱く、状況次第で中立〜わずかにプラス、という結果です。
8. まとめ
- 推論させないLLMに対して、質問文を2回繰り返すだけで改善が出るケースが多い
- 実験では 47/70で有意改善・0敗
- しかも 出力が長くならず、レイテンシも概ね増えない(例外は長文×一部モデル)
- 使いどころは「即答系」「多肢選択」「長い入力の読み落としが怖い場面」
- 難問の推論は別途step-by-stepが有効だが重い。軽く底上げしたいならPrompt Repetitionは候補になる
参考(一次情報)
※リンクはコードブロックに入れています
arXiv: 2512.14982
Prompt Repetition Improves Non-Reasoning LLMs
https://arxiv.org/abs/2512.14982
https://arxiv.org/pdf/2512.14982